
harsha kokel
Active Advice Seeking for Inverse Reinforcement Learning
My notes on Phillip Odom and Sriraam Natarajan, AAMAS 2016.
In Kunapali et al 2013, authors present a way of incorporating advice in Inverse Reinforcement Learning (IRL) by extending IRL formulation to include constraints based on the expert’s advice of preferred and avoided actions, state and reward. Odom et al 2017 expands on Kunapali et al (2013)’s formulation of preferred and avoided actions by seeking the advice in active learning setting. The paper proposes a active advice-seeking framework, where instead of seeking mere-label from the expert for selected example as done in active learning, they seek advice (set of preferred and avoided labels) over set of examples. Two clear advantages of active advice-seeking framework over the traditional active learning setting is that expert can provide multiple advice and that advice is generalized over set of states.
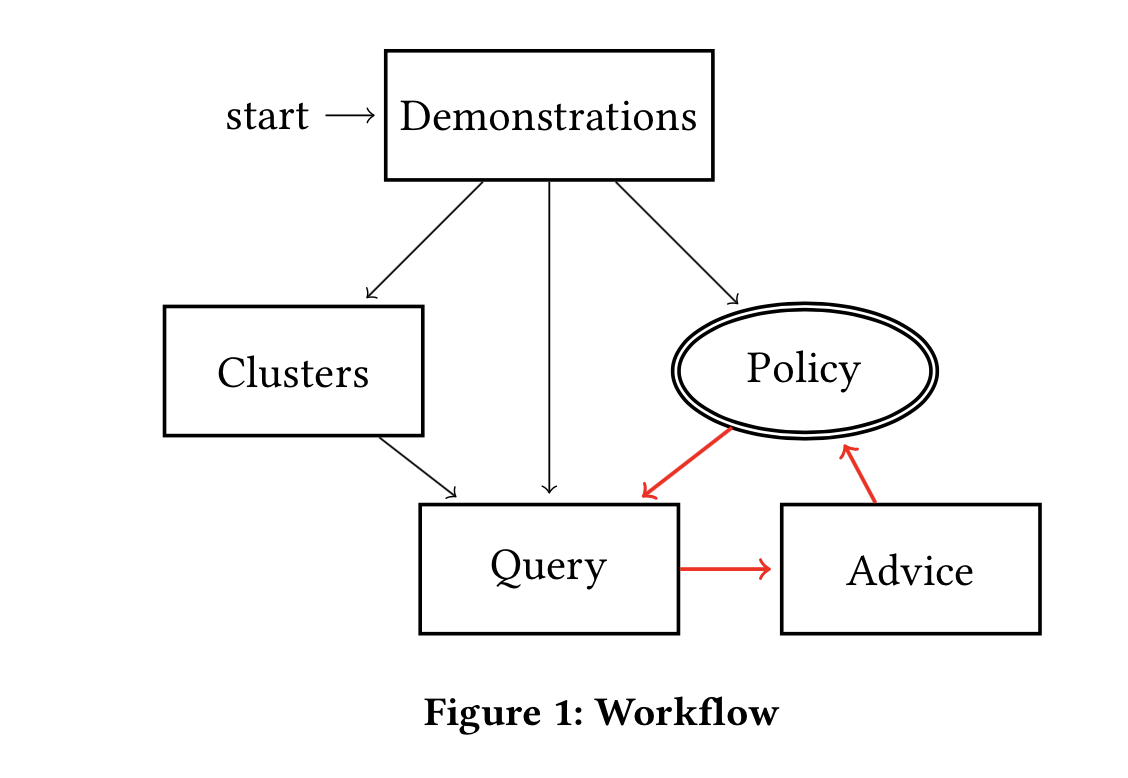
The workflow of the paper is shown in the figure above. First the states are clustered together, heuristic proposed is to cluster the states which has similar action distribution, and authors use the action distribution of the demonstrations as a proxy. Then, a policy is learnt only from the demonstrations. Next, query is generated by selecting the state cluster with the maximum uncertainty measure (equation below). This uncertainty measure is an artifact of the entropy of the distribution of actions in demonstration and the entropy of the policy
\[ U_{s}\left(s_{i}\right)=\underbrace{w_{p} F\left(s_{i}\right)}{\text{demonstration}}+\underbrace{\left(1-w{p}\right) G\left(s_{i}\right)}_{\text{policy}} \]
Advice, set of preferred and avoid actions, is received on the query and a new policy is learnt based on the advice and the demonstrations. Query generation, advice seeking and policy learning steps are repeated again and again till the query budget surpasses.
Active-advise seeking is compared against learning only from trajectories (standard IRL), advice over single state (active learning) and advice over random clusters. This paper show empirically (on 4 datasets) that the active-advice seeking framework proposed is superior to the other approaches, albeit sensitive to the quality of the cluster.
Critique
The paper introduces first of its kind framework to actively solicit advice from the human experts and is a very important contribution towards showing the need for Human-In-The-Loop approaches. Abstract MDPs and Relational RL have a natural way to reference a set of states by abstract state and a horn clause respectively. This paper shows that in case of propositional RL, this can be achieved by clustering states using K-Means. This could be a valuable direction as it provides best of both worlds (Propositional & Relational RL). The clustering heuristic does not have a theoretical justification but empirical evaluations show that it performs well for IRL. This is reasonable considering that we are learning a policy from the demonstration and hence the states with similar actions are grouped together. However, this might not be the case always. So, a more matured clustering technique might be useful.
The clustering is done only once, based on the demonstrations which might be sub-optimal. An iterative clustering might have been more challenging but one wonders if that would have helped achieve optimality especially in the drone-flying domain where there is lot of scope to improve.
In this framework, the advice is generalized over the clustered states, but in real-world I imagine an advice can be generalized beyond clusters and hence a way to generalize advice across states might be an interesting future direction.
Also, I would like to appreciate the complexity of the drone flying domain. Here, as the drone is supposed to visit the corners in a specific order, the preferred action at any location will be different based on the next corner being targeted. Paper lacks the details of how the state encoding was done, it would have been interesting to see some details. The expert advice will also have to be carefully tailored to achieve the corner sub-goal.
References
- Phillip Odom and Sriraam Natarajan, Active Advice Seeking for Inverse Reinforcement Learning, AAMAS 2016
- Gautam Kunapuli, Phillip Odom, Jude W Shavlik, and Sriraam Natarajan, Guiding autonomous agents to better behaviors through human advice, ICDM 2013