
harsha kokel
Hierarchical Reinforcement Learning
An overview of Hierarchical RL. Written as part of Advanced RL course by Prof. Sriraam Natarajan.
Standard RL planning suffers from the curse of dimensionality when the action space is too large and/or state space is infeasible to enumerate. Humans simplify the problem of planning in such complex conditions by abstracting away details which are not relevant at a given time and decomposing actions into hierarchies. Several researchers have proposed to model the temporal-abstraction in RL by composing some form of hierarchy over actions space (Dietterich 1998, Sutton et al 1998, Parr and Russell 1998). By modeling actions as hierarchies, researchers extended the primitive action space by adding abstract actions. Options framework (Sutton et al 1998), refer the abstract actions as options, MAXQ (Dietterich 1998) refer to them as tasks and Hierarchical Abstract Machines (HAM) (Parr and Russell 1998) refers to them as choices.
Common theme among these papers is to extend the Markov Decision Process (MDP) to Semi-Markov Decision Process (SMDP), where actions can take multiple time steps. As compared to MDP, which only allow actions of a discrete time-steps, SMDP allows modeling temporally abstract actions of varying length over a continuous time. As represented in first two trajectories of figure below. By constraining/extending the action space of the MDP over primitive and abstract actions, hierarchical RL approaches superimpose MDPs and SMDPs as shown in last trajectory.
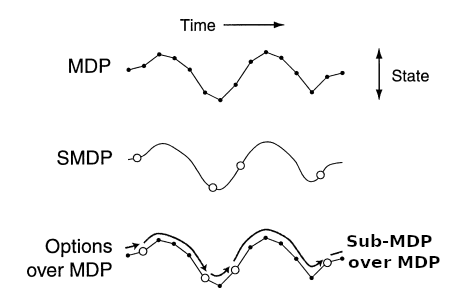
Semi-Markov Decision Process
HRL is appealing because the abstraction of actions facilitate accelerated-learning and generalization while exploiting the structure of the domain.
Faster learning is possible because of the compact-representation. Original MDP is broken into sub-MDP with less states (abstracted states hide irrelevant details and hence reduce the number of states) and less actions. For example, in the Taxi Domain introduced in (Dietterich 1998), if the agent is learning to navigate to a location it does not matter if the passenger is being picked or dropped. Details about location of passenger are irrelevant and hence the state space is reduced.
Better generalization is possible because of the abstracted actions. In the taxi domain, because we define an abstract action called $Navigation$, agent learns a policy to navigate the taxi to a location. Once that policy is learned for navigation to pick up a passenger, the same policy can be leveraged when then agent is navigating to drop the passenger.
Two important promises of HRL are prior-knowledge and transfer-learning. A complex task in HRL is decomposed into hierarchy (usually by humans). Hence, it is easier for humans to provide some prior on actions from their domain knowledge. Different levels of hierarchy encompass different knowledge and hence ideally it would be easier to transfer that knowledge across different problems.
One minor limitation of HRL is that all the hierarchical methods converge to hierarchically optimal policy, which can be a sub-optimal policy. For example in the taxi domain, if the hierarchy decomposition states first navigate to the passenger location and then navigate to the fuel location, the HRL agent will find an optimal policy to do that in exactly that order. This policy might be sub-optimal given an initial state which is closer to the fuel location. This limitation is an artifact of restricting the action space while solving sub-MDPs. If full action space is available in all the MDPs, the exponential increase in computational overhead makes the learning infeasible.
Max-Q framework has a clear hierarchical decomposition of tasks, while the options-framework do not have clear hierarchy. Options framework achieves temporal abstraction of actions, Max-Q framework additionally also achieves state abstractions. While there has been an attempt on discovering and transferring the Max-Q hierarchies (Mehta et al. 2008), learning Max-Q hierarchies directly from the trajectories is still an open problem. For large and complex problem it might be a challenge to provide the task hierarchy or options and their termination conditions.
References
- [Dietterich 1998] Dietterich, T. G. 1998. The maxq methodfor hierarchical reinforcement learning. In ICML.
- [Sutton, Precup, and Singh 1998] Sutton, R. S.; Precup, D.;and Singh, S. P. 1998. Intra-option learning about tempo-rally abstract actions. In ICML.
- [Parr and Russell 1998] Parr, R., and Russell, S. J. 1998. Reinforcement learning with hierarchies of machines. In NeurIPS
- [Mehta et al. 2008] Mehta, N.; Ray, S.; Tadepalli, P.; and Di-etterich, T. 2008. Automatic discovery and transfer of maxq hierarchies. In ICML.
- The Promise of Hierarchical Reinforcement Learning by Yannis Flet-Berlia in The Gradient
- Hierarchical Reinforcement Learning lecture by Doina Precup on YouTube
Previous post
Active Advice Seeking for Inverse Reinforcement Learning
Next post
Fitted Q and Batch Reinforcement Learning